물론 MRR 을 활용하여 NL join에서 driven table 로의 random access 를 줄이는 BKA (Batched Key Access )
NL join 의 대상을 작은 block 으로 나누어 block 하나씩 join 하는 hash join을 어느정도 따라하려했던 BNL(Block Nested Loop) 방식이 있기는 하지만
어디까지나 nested loop join이 기반이며 hash join과 merge join 을 대체할 수는 없었습니다.
그러나 8.0.18 버전으로 올라오면서 드디어 hash join 을 지원하게 되었습니다.
Hash join 이란
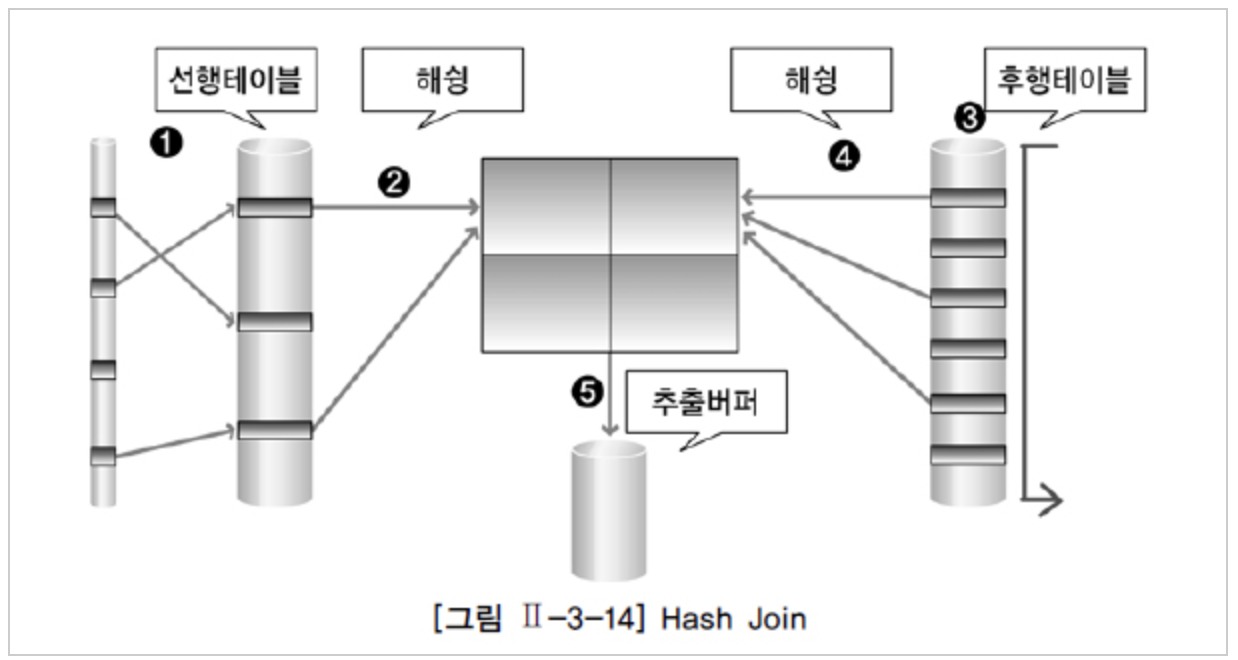 ( 출처 : http://www.gurubee.net/lecture/2388 )
* 선행 테이블의 값, 후행 테이블의 값에 대해 해쉬 값이 동등한지를 확인하기 때문에 동등조건에 대해서만 join 가능
* 후행 테이블에 인덱스가 없을 때도 사용 가능
* 조인에 성공하면 join_buffer에 넣는데 메모리에 적재할 수 있는 크기보다 커지면 디스크에 저장함 (join_buufer_size 튜닝 중요)
* left outer join , right outer join 불가
( 출처 : http://www.gurubee.net/lecture/2388 )
* 선행 테이블의 값, 후행 테이블의 값에 대해 해쉬 값이 동등한지를 확인하기 때문에 동등조건에 대해서만 join 가능
* 후행 테이블에 인덱스가 없을 때도 사용 가능
* 조인에 성공하면 join_buffer에 넣는데 메모리에 적재할 수 있는 크기보다 커지면 디스크에 저장함 (join_buufer_size 튜닝 중요)
* left outer join , right outer join 불가
Hash join test
* optimizer_switch 확인mysql> show variables like 'optimizer_switch';
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=onCREATE TABLE t1 (
id int(11) NOT NULL AUTO_INCREMENT ,
c1 int(11) NOT NULL DEFAULT '0',
c2 int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
KEY idx_c1 (c1)
) ENGINE=InnoDB;
CREATE TABLE t2 (
id int(11) NOT NULL AUTO_INCREMENT ,
c1 int(11) NOT NULL DEFAULT '0',
c2 int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (id),
KEY idx_c1 (c1)
) ENGINE=InnoDB;
insert into test.t1 select null,round(rand()*100),round(rand()*1000)
from information_schema.columns a1, information_schema.columns b1
limit 1000000;hash join 확인
* explain format=tree 으로 봐야 hash join plan 확인가능( 기존에 사용하던 단순 explain과 BNL은 사라질 것이라고함
https://bugs.mysql.com/bug.php?id=97299)
mysql> explain format=tree select count(*) from t1 join t2 on t1.c2 = t2.c2\G
*************************** 1. row ***************************
EXPLAIN: -> Aggregate: count(0)
-> Inner hash join (t1.c2 = t2.c2) (cost=99689553395.24 rows=99689442783)
-> Table scan on t1 (cost=0.02 rows=998490)
-> Hash
-> Table scan on t2 (cost=100329.20 rows=998402)
1 row in set (0.00 sec)
mysql> select count(*) from t1 join t2 on t1.c2 = t2.c2;
+-----------+
| count(*) |
+-----------+
| 999567585 |
+-----------+
1 row in set (41.68 sec)* explain 으로는 hash join이 안보임
mysql> explain select count(*) from t1 join t2 on t1.c2 = t2.c2
-> ;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 131467 | 100.00 | NULL |
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 131472 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)non-hash join 일 때
mysql> set optimizer_switch='hash_join=off';
Query OK, 0 rows affected (0.00 sec)
mysql> explain format=tree select count(*) from t1 join t2 on t1.c2 = t2.c2\G
*************************** 1. row ***************************
EXPLAIN:
1 row in set (0.00 sec)
mysql> explain select count(*) from t1 join t2 on t1.c2 = t2.c2;
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 131467 | 100.00 | NULL |
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 131472 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)
mysql> select * from information_schema.processlist where id=15;
+----+------+-----------+------+---------+------+-----------+--------------------------------------------------+
| ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO |
+----+------+-----------+------+---------+------+-----------+--------------------------------------------------+
| 15 | root | localhost | test | Query | 1633 | executing | select count(*) from t1 join t2 on t1.c2 = t2.c2 |
+----+------+-----------+------+---------+------+-----------+--------------------------------------------------+
1 row in set (0.00 sec)41초 걸렸던 hash join 과는 달리 1600초 이상 기다려도 완료안됨. 작업 취소!
* hash join on /off
mysql> set optimizer_switch='hash_join=off';
mysql> select /*+ HASH_JOIN (t1,t2) */ count(*) from t1 join t2 on t1.c2 = t2.c2
mysql> select /*+ NO_HASH_JOIN (t1,t2) */ count(*) from t1 join t2 on t1.c2 = t2.c2